






N-Gram......
Pertama kali mendengarnya, terdengar asing ditelinga saya dan saya berfikir, kok namanya seperti timbangan ya, hehe... Namun lama kelamaan menjadi tuntutan bagi saya. Sesuatu yang mau tidak mau harus saya pelajari untuk mendukung studi saya.hehe....
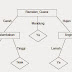
N-Gram adalah sebuah proses pemecah kata yang tergolong popular. N dalam n-gram bisa diberi nilai secara acak sesuai dengan keinginan pengguna. Bobot pada N akan digunakan untuk memecah sebuah kalimat menjadi kecil-kecil sesuai dengan pemberian bobot pada N. Pada gambar diatas adalah proses N-Gram dengan jumlah N sebanyak 3 (Trigram).
Proses pemberian bobot pada N-Gram sangatlah bervariatif tergantung pada data yang akan diproses, bobot pada N juga akan mempengaruhi keakuratan pada hasil learning, jadi memilih bobot yang tepat adalah sebuah proses yang bisa dikatakan sulit. Karena salah memberikan bobot hasil yang didapat tidak akan sesuai harapan, bahkan mendekati harapan.
Pemrosesan n-gram
Pada pemrosesan n-gram akan diberikan contoh dengan kata "aku sayang kamu", maka akan diproses sebagai berikut:
Dari hasil yang didapat akan dilakukan proses pembobotan dari frekuensi kemunculannya, semakin besar kemunculan suatu kata maka tingkat similarity terhadap dokumen akan semakin baik.
N-Gram adalah sebuah proses pemecah kata yang tergolong popular. N dalam n-gram bisa diberi nilai secara acak sesuai dengan keinginan pengguna. Bobot pada N akan digunakan untuk memecah sebuah kalimat menjadi kecil-kecil sesuai dengan pemberian bobot pada N. Pada gambar diatas adalah proses N-Gram dengan jumlah N sebanyak 3 (Trigram).
Proses pemberian bobot pada N-Gram sangatlah bervariatif tergantung pada data yang akan diproses, bobot pada N juga akan mempengaruhi keakuratan pada hasil learning, jadi memilih bobot yang tepat adalah sebuah proses yang bisa dikatakan sulit. Karena salah memberikan bobot hasil yang didapat tidak akan sesuai harapan, bahkan mendekati harapan.
Pemrosesan n-gram
Pada pemrosesan n-gram akan diberikan contoh dengan kata "aku sayang kamu", maka akan diproses sebagai berikut:
Bobot
|
Hasil
|
Unigram
|
a, k, u, s, a, y, a, n, g,
k, a, m, u
|
Bigram
|
ak, ku, us, sa, ay, ya,
an, ng, gk, ka, am, mu
|
rigram
|
aku, kus, usa, say, aya,
yan, ang, ngk, gka, kam, amu
|
Dst….
|
Dari hasil yang didapat akan dilakukan proses pembobotan dari frekuensi kemunculannya, semakin besar kemunculan suatu kata maka tingkat similarity terhadap dokumen akan semakin baik.







0 Komentar:
Post a Comment